Технологии извлечения, очистки, восстановления, бизнес - анализа и передачи информации
Очистка данных, также называемая очисткой или очисткой данных, занимается обнаружением и удалением ошибок и несоответствия данных в целях повышения качества данных. Проблемы с качеством данных присутствуют в единичных коллекции данных, такие как файлы и базы данных, например, из-за неправильного написания при вводе данных, отсутствующей информации или другие неверные данные. Когда необходимо интегрировать несколько источников данных, например, в хранилищах данных, объединить системы баз данных или глобальные информационные веб-системы, потребность в очистке данных возрастает существенно. Это связано с тем, что источники часто содержат избыточные данные в разных представлениях. Чтобы обеспечить доступ к точным и непротиворечивым данным, объединение различных представлений данных и устранение дублирующейся информации становится необходимо.
Введение в ETL
- ETL (extraction, transformation, loading)
-
комплекс методов, реализующих процесс переноса исходных данных из различных источников в аналитическое приложение или поддерживающее его хранилище данных.
Извлечение данных из разнотипных источников и перенос их в хранилище данных с целью дальнейшей аналитической обработки связаны с рядом проблем, основными из которых являются нижеследующие.
Исходные данные расположены в источниках самых разнообразных типов и форматов, созданных в различных приложениях, и, кроме того, могут использовать различную кодировку, в то время как для решения задач анализа данные должны быть преобразованы в единый универсальный формат, который поддерживается ХД и аналитическим приложением.
Данные в источниках обычно излишне детализированы, тогда как для решения задач анализа в большинстве случаев требуются обобщенные данные.
Исходные данные, как правило, являются «грязными», то есть содержат различные факторы, которые мешают их корректному анализу.
Поэтому для переноса исходных данных из различных источников в ХД следует использовать специальный инструментарий, который должен извлекать данные из источников различного формата, преобразовывать их в единый формат, поддерживаемый ХД, а при необходимости — производить очистку данных от факторов, мешающих корректно выполнять их аналитическую обработку. Такой комплекс программных средств получил обобщенное название ETL (от англ. extraction, transformation, loading — «извлечение», «преобразование», «загрузка»). Сам процесс переноса данных и связанные с ним действия называются ETL-процессом, а соответствующие программные средства — ETL-системами.
Основные цели и задачи процесса ETL
Приложения ETL извлекают информацию из одного или нескольких источников, преобразуют ее в формат, поддерживаемый системой хранения и обработки, которая является получателем данных, а затем загружают в нее преобразованную информацию. Изначально ETL-системы использовались для переноса информации из более ранних версий различных информационных систем в новые. В настоящее время ETL-системы все более широко применяются именно для консолидации данных с целью их дальнейшего анализа. Очевидно, что поскольку ХД могут строиться на основе различных моделей данных (многомерных, реляционных, гибридных), то и процесс ETL должен разрабатываться с учетом всех особенностей используемой в ХД модели. Кроме того, желательно, чтобы ETL-система была универсальной, то есть могла извлекать и переносить данные как можно большего числа типов и форматов.
Независимо от особенностей построения и функционирования ETL-система должна обеспечивать выполнение трех основных этапов процесса переноса данных (ETL-процесса).
Извлечение данных. На этом этапе данные извлекаются из одного или нескольких источников и подготавливаются к преобразованию. Следует отметить, что для корректного представления данных после их загрузки в ХД из источников должны извлекаться не только сами данные, но и информация, описывающая их структуру, из которой будут сформированы метаданные для хранилища.
Преобразование данных. Производятся преобразование форматов и кодировки данных, а также их обобщение и очистка.
Загрузка данных — запись преобразованных данных в соответствующую систему хранения.
Перемещение данных в процессе ETL можно разбить на последовательность процедур, представленных следующей функциональной схемой:
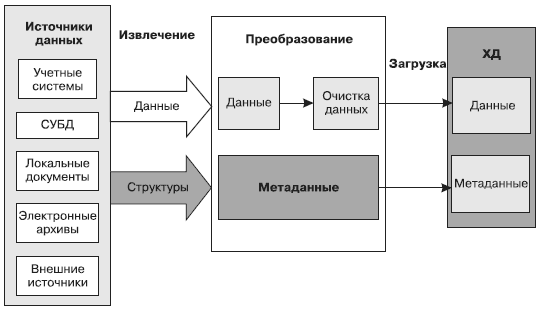
Извлечение. Данные извлекаются из источников и загружаются в промежуточную область.
Поиск ошибок. Производится проверка данных на соответствие спецификациям и возможность последующей загрузки в ХД.
Преобразование. Данные группируются и преобразуются к виду, соответствующему структуре ХД.
Распределение. Данные распределяются на несколько потоков в соответствии с особенностями организации процесса их загрузки в ХД.
Вставка. Данные загружаются в хранилище-получатель.
С точки зрения процесса ETL архитектуру ХД можно представить в виде трех компонентов, таких как:
источник данных — содержит структурированные данные в виде отдельной таблицы, совокупности таблиц или просто файла, данные в котором, например, упорядочены в типизированные столбцы, отделенные друг от друга некоторыми символами-разделителями;
промежуточная область — содержит вспомогательные таблицы, создаваемые временно и исключительно для организации процесса выгрузки;
получатель данных — ХД или просто БД, в которую должны быть помещены извлеченные данные.
Перемещение данных от источника к получателю называется потоком данных. Требования к организации потоков данных описываются аналитиком.
ETL часто рассматривают как просто подсистему переноса данных из различных источников в централизованное хранилище. Что касается самих хранилищ данных, то они, строго говоря, не связаны с решением какой-либо конкретной аналитической задачи. Задача хранилища — обеспечивать надежный и быстрый доступ к данным, поддерживать их хронологию, целостность и непротиворечивость. Поэтому на первый взгляд ETL оказывается отделенным от собственно анализа данных. Однако такой взгляд на ETL не позволит добиться преимуществ, которые можно получить, если рассматривать его как неотъемлемую часть аналитического процесса.
Опытный аналитик знает особенности и характер данных, циркулирующих на различных уровнях корпоративной информационной системы, частоту их обновления, степень «загрязненности», уровень их значимости и т.д. Это дает ему возможность с помощью комбинации различных методов преобразования данных в ETL добиться достаточного уровня обобщения и качества данных, попавших в хранилище, выбрать оптимальный регламент и технические требования его пополнения. Последнее особенно важно для организаций со сложной многоуровневой филиальной структурой и большим количеством подразделений.
Например, если известно, что информация, поступающая из определенных подразделений фирмы, является самой важной и полезной, а также часто анализируется, то в регламент переноса данных в хранилище можно внести соответствующие приоритеты.
Таким образом, ETL следует рассматривать не только как процесс переноса данных из одного приложения в другое, но и как инструмент их подготовки к анализу.
Критерии оценки качества данных
Чтобы разработать методику очистки данных в процессе ETL, необходимо определить критерии оценки их качества. Одним из таких критериев является критичность ошибок. В этой связи данные могут быть разделены на три категории:
данные высокого качества, не нуждающиеся в очистке;
данные, содержащие критичные ошибки, из-за которых они в принципе не могут быть загружены в ХД (например, буква или пробел в числовом значении, неправильный разделитель целой и дробной частей числа и т.д.). То есть критичными являются ошибки, которые делают невозможной дальнейшую работу с данными;
данные, содержащие некритичные ошибки, которые не мешают их загрузке в ХД, но при этом данные являются некорректными с точки зрения их анализа (аномальные значения, пропуски, дубликаты, противоречия и т.д.). Некритичные ошибки могут быть исправлены в процессе анализа данных средствами аналитической системы.
Существует несколько проблем, из-за которых данные нуждаются в очистке. Наиболее широко распространены проблемы, связанные с нарушением структуры данных:
корректность форматов и представлений данных;
уникальность первичных ключей в таблицах БД;
полнота и целостность данных;
полнота связей;
соответствие некоторым аналитическим ограничениям и т.д.
Для каждого структурного уровня данных — отдельной ячейки, записи, целой таблицы, отдельной БД или множества БД — характерны свои факторы, снижающие качество данных. Наиболее типичные ошибки, соответствующие структурным единицам БД, представлены в таблице.
| Ячейка | Запись | Таблица | Отдельная БД | Множество БД |
|---|---|---|---|---|
| Орфографические ошибки | Противоречия между ячейками | Дублирование записей | Целостность данных | Несоответствия структуры данных |
| Пропуски в данных | Противоречивые записи | Противоречия | Одинаковые наименования различных атрибутов | |
| Фиктивные значения | Различное представление однотипных данных | |||
| Логические несоответствия | Различная временная шкала | |||
| Закодированные значения | ||||
| Составные значения |
На уровне отдельной ячейки таблицы наиболее характерны следующие ошибки.
Пропуски данных — отсутствие данных в тех ячейках, где они должны быть. Пропуски могут быть вызваны ошибкой оператора или отсутствием соответствующей информации. Например, что означает отсутствие информации о продажах в супермаркете на определенную дату? Если в этот день магазин был закрыт, то есть продаж не было, в соответствующей ячейке должен стоять ноль. Если же магазин работал, то, скорее всего, имеет место ошибка оператора. Однако при автоматической загрузке огромного количества данных, что имеет место в большинстве корпоративных систем, разобраться с каждым отдельным случаем пропуска данных невозможно. Поэтому на этапе очистки данных в ETL необходимо разработать методику восстановления пропущенных данных, которая как минимум делала бы их корректными с точки зрения совместимости со структурой хранилища. Что касается корректности с точки зрения анализа, то большинство аналитических систем содержит средства восстановления пропущенных данных способом, который предпочтет аналитик (начиная от установки значения вручную до применения сложных статистических методов).
Фиктивные значения — данные, не имеющие смысла, никак не связанные с описываемым ими бизнес-процессом. Подобная ситуация возможна, если оператор системы OLTP, не располагая необходимой информацией, ввел в ячейку произвольную последовательность символов. Оператор бывает вынужден это сделать, когда система не позволяет продолжать работу, пока соответствующая ячейка не будет заполнена. Так, если клиент забыл указать в анкете возраст, то оператор может ввести значение 0 или 999. При этом лучше, если значение явно «не лезет ни в какие ворота», поскольку в таком случае вероятность того, что оно будет принято за реальное, уменьшается. Вообще, обнаружить и отфильтровать фиктивные значения довольно трудно, поскольку понятие «смысл» является субъективным и не поддается формализации. Поэтому на этапе очистки данных средствами ETL можно выработать только общие формальные методы обнаружения фиктивных значений и борьбы с ними. Например, можно установить правило: «Если возраст клиента больше 150, то заменить его на значение 0». Когда при последующем анализе аналитик встретит такое значение, он поймет, что значение фиктивное, и примет меры к его замене на более правдоподобное (например, среднее по выборке). Существует и другой способ борьбы с фиктивными значениями. Можно проинструктировать операторов OLTP-систем или персонал, который занимается сводками данных в офисных приложениях, что при отсутствии реальных данных должен вводиться специальный код, который при обработке в процессе ETL распознавался бы как фиктивное значение. Затем к таким данным можно применить обработку, предписанную аналитиком. Наконец, если фиктивные значения являются аномальными (что чаще всего и имеет место), то они могут быть обнаружены и скорректированы средствами аналитической системы.
Логические несоответствия возникают, если значение в ячейке не соответствует логическому смыслу поля таблицы. Например, вместо наименования фирмы указан ее банковский счет.
Закодированные значения — сокращения, аббревиатуры, замена наименований числовыми кодами.
Составные значения появляются в файлах, где структура полей жестко не задана, например в обычных текстовых файлах, электронных таблицах и т.д. Составное значение может получиться, если оператор регистрационной системы ошибочно ввел два отдельных значения или более в ячейку, предназначенную для одного значения. Например, в системе предусмотрены отдельные поля для фамилии, имени и отчества клиента, а неопытный оператор ввел все эти значения в одно поле Фамилия. Другой вариант: для каждого из элементов адреса клиента предусмотрены отдельные поля, а весь адрес оказался введен в поле Индекс.
На уровне записи возникают в основном проблемы противоречивости данных в различных ячейках. Например, сумма, на которую был продан товар, не соответствует произведению цены за единицу и количества проданных единиц.
На уровне таблицы основными проблемами являются дублирующие и противоречивые записи.
Дубликаты — это полностью идентичные записи. Сами по себе они не вызывают нарушений в структуре данных, и их наличие не является критичным. Однако дубликаты также могут вызвать ряд проблем.
Увеличивается объем данных и, соответственно, время, требуемое на их загрузку и обработку.
Временные затраты при аналитической обработке дубликатов увеличиваются, при этом качество анализа не повышается.
Дубликаты могут ухудшить качество аналитических моделей, основанных на обучении (нейронные сети, деревья решений). Если значительный процент обучающей выборки для таких моделей будут составлять дублирующие записи, то результаты обучения могут ухудшиться.
Аналитические системы обычно содержат средства для обнаружения и удаления дублирующих записей. Поэтому если в процессе ETL борьба с дубликатами не была предусмотрена, это можно будет сделать при подготовке данных к анализу непосредственно в аналитической системе.
Противоречивыми являются записи, которые для двух различных объектов содержат одинаковые значения уникальных атрибутов. Например, в базе данных клиентов для двух разных организаций указаны одинаковые банковские реквизиты.
На уровне отдельной БД основной проблемой является нарушение целостности данных, которое заключается в том, что происходит рассогласование между различными объектами БД. Например, если в БД есть документ, сопровождающий сделку с каким-либо клиентом, то, как правило, при создании нового документа имя клиента не вводится вручную, а выбирается из списка клиентов, содержащегося в другой таблице БД и открывающегося при заполнении соответствующего поля. В результате документ содержит не собственно имя клиента, а ссылку на соответствующий объект другой таблицы. Если по какой-либо причине объект (то есть запись о клиенте) будет удален, то документ не сможет быть сформирован, из-за того что объект, на который имеется ссылка, оказывается недоступен.
На уровне множества БД возникают проблемы, связанные с отличиями структуры данных в различных базах:
различные правила назначения имен полей (например, различное число символов, допустимых в имени поля, наличие пробелов, символов национальных алфавитов и т.д.);
различия в используемых типах полей;
одинаковые названия полей для разных атрибутов (например, в одном источнике данных поле Name содержит названия фирм, а в другом — наименования товаров);
различная временная шкала (например, данные, описывающие один и тот же бизнес-процесс, хранятся в двух разных файлах, но в одном из них представлена ежедневная информация, а в другом — еженедельная).
Стратегия очистки данных должна разрабатываться с учетом особенностей предметной области, функционирования OLTP-систем и порядка сбора данных. Например, принимая решение о включении в процесс обработки данных ETL средств для борьбы с дубликатами, аналитик должен выяснить, могут ли в бизнес-процессе возникать идентичные объекты или события, происходящие в одном временном интервале. Если да, то две одинаковые записи, определяемые как дубликаты, могут описывать разные объекты или события. Очевидно, что в этом случае к обработке дубликатов следует подходить с осторожностью, чтобы не потерять полезную информацию.
Кроме того, необходимо помнить, что полностью очистить данные удается очень редко. Существуют проблемы, которые не получается решить независимо от степени приложенных усилий. Бывают случаи, когда некорректное применение методов очистки данных только усугубляет ситуацию. Иногда использование очень сложных алгоритмов очистки увеличивает время переноса данных в ХД до неприемлемой величины. Поэтому не всегда следует стремиться к полной очистке данных. Лучше обеспечить компромисс между сложностью используемых алгоритмов, затратами на вычисление, временем, требуемым на очистку, и ее результатами. Если достоверность каких-то данных не влияет на результаты анализа, то от их очистки, возможно, следует вообще отказаться.
Преобразование данных в ETL
Этап ETL-процесса, следующий за извлечением, — преобразование данных. Его цель — подготовка данных к размещению в ХД и приведение их к виду, наиболее удобному для последующего анализа. При этом должны учитываться некоторые выдвигаемые аналитиком требования, в частности, к уровню качества данных. Поэтому в процессе преобразования может быть задействован самый разнообразный инструментарий, начиная от простейших средств ручного редактирования данных до систем, реализующих весьма сложные методы обработки и очистки данных.
В процессе преобразования данных в рамках ETL чаще всего выполняются следующие операции:
преобразование структуры данных;
агрегирование данных;
перевод значений;
создание новых данных;
очистка данных.
Преобразование структуры данных
Во многих случаях данные поступают в хранилище, интегрируясь из множества источников, которые создавались с помощью различных программных средств, методологий, соглашений, стандартов и т.д. Данные из таких источников могут отличаться своей структурной организацией: соглашениями о назначении имен полей и таблиц, порядком их описания, форматами, типами и кодировкой данных, например точностью представления числовых данных, используемыми разделителями целой и дробной частей, разделителями групп разрядов и т.д. Следовательно, во многих случаях извлеченные данные непригодны для непосредственной загрузки в ХД из-за отличия их структуры от структуры соответствующих целевых таблиц ХД.
При этом если таблицы фактов чаще всего соответствуют требованиям ХД, то таблицы измерений нуждаются в дополнительной обработке и, может быть, объединении.
Так, если в источнике, полученном из одного филиала, информация о покупателях хранится в поле Customer_Id, а в источнике, полученном из другого филиала, — в поле Clients_Name, то для создания одного измерения Покупатель придется решать задачу их объединения.
Дополнительная обработка структуры данных также требуется в ситуации, когда одно подразделение фирмы представляет информацию о цене и количестве проданных товаров, а другое — о количестве товаров и общей сумме продаж. В таком случае потребуется привести информацию о продажах, полученную из обоих источников, к общему виду.
Агрегирование данных
Как правило, в качестве источников данных для хранилищ выступают системы оперативной обработки данных (OLTP-системы), учетные системы, файлы различных СУБД, локальные файлы отдельных пользователей и т.д. Общим свойством всех этих источников является то, что они содержат данные с максимальной степенью детализации — сведения о ежедневных продажах или даже о каждом факте продажи в отдельности, об обслуживании каждого клиента и т.д. Распространено мнение, что такое детальное воспроизведение событий в исследуемом бизнес-процессе только пойдет на пользу, поскольку данные никогда не бывают лишними и чем больше их будет собрано, тем точнее окажутся результаты анализа.
Это не совсем так. Элементарные события, из которых состоит бизнес-процесс, например обслуживание одного клиента, выполнение одного заказа и т.д., которые также называют атомарными (то есть неделимыми), по своей сути являются случайными величинами, подверженными влиянию множества различных случайных факторов — от погоды до настроения клиента. Следовательно, информация о каждом отдельном событии в бизнес-процессе практически не имеет ценности. Действительно, на основании информации о продажах за один день нельзя сделать вывод обо всех особенностях торговли. Точно так же нельзя выработать стратегию работы с клиентами на основе исследования поведения одного клиента.
Иными словами, для достоверного описания предметной области использование данных с максимальным уровнем детализации не всегда целесообразно, поэтому наибольший интерес для анализа представляют данные, обобщенные по некоторому интервалу времени, по группе клиентов, товаров и т.д. Такие обобщенные данные называются агрегированными (иногда агрегатами), а сам процесс их вычисления — агрегированием.
В результате агрегирования большое количество записей о каждом событии в бизнес-процессе заменяется относительно небольшим количеством записей, содержащих агрегированные значения. Например, вместо информации о каждой из 365 ежедневных продаж в году в результате агрегирования будут храниться 52 записи с обобщением по неделям, 12 — по месяцам или 1 — за год. Если цель анализа — разработка прогноза продаж, то для краткосрочного оперативного прогноза достаточно использовать данные по неделям, а для долгосрочного стратегического прогноза — по месяцам или даже по годам.
Фактически при агрегировании производится объединение нескольких записей в одну с вычислением агрегированного значения на основе значений каждой записи. При вычислении агрегатов может быть использовано несколько способов.
Среднее — для данных, расположенных в пределах интервала, в котором они обобщаются, вычисляется среднее значение. Затем все записи из данного интервала заменяются одной, содержащей их среднее значение.
Сумма — агрегируемые записи заменяются одной, в которой указывается сумма агрегируемых значений.
Максимум — в результирующей записи остается максимальное значение из всех объединяемых.
Минимум — в результирующей записи остается минимальное значение из всех объединяемых.
Количество уникальных значений — результатом агрегирования будет число уникальных значений, появляющихся в ячейках одного и того же поля. Так, для поля, содержащего информацию о профессии клиента, данный способ агрегирования покажет, сколько раз та или иная профессия появлялась в списке. Например, если в 25 записях в поле профессия имело место значение Системный аналитик, а в 50 — Менеджер, то в результате агрегирования мы получим число 2.
Количество — результатом агрегирования будет число записей, содержащихся в поле. В приведенном выше примере с профессиями клиентов при этом варианте агрегирования получим 75.
Медиана — вычисляется медиана агрегируемых значений. Медиана представляет собой порядковую статистику, рассчитываемую следующим образом. Набор агрегируемых значений, например продажи по дням недели, сортируется в порядке возрастания. Тогда медианой будет центральный элемент упорядоченного набора, если этот набор содержит нечетное количество значений, или среднее двух центральных элементов, если число элементов четное. Например, пусть каждый день в течение недели продажи составляли {100, 120, 115, 119, 107, 131, 102}. Тогда для определения медианы нужно выстроить эти значения по возрастанию: {100, 102, 107, 115, 119, 120, 131}. Значение центрального элемента полученной последовательности, то есть 115, и будет медианой. Если продажи осуществлялись только 6 дней в неделю (воскресенье — выходной), то будет получена последовательность из четного числа значений {100, 107, 115, 119, 120, 131}. В этом случае медиана будет равна: (115 + 119) / 2 = 117.
Из всех возможных вариантов агрегирования следует выбрать наиболее значимые с точки зрения планируемых направлений анализа, а от остальных отказаться. Очевидно, можно отказаться от агрегатов, которые имеют малое число подчиненных агрегированных значений (например, агрегирование ежемесячных продаж за квартал), поскольку их легко вычислить в процессе анализа. Или, наоборот, можно отказаться от агрегатов с максимальной степенью детализации (например, агрегирование ежедневных продаж). Второй вариант наиболее предпочтителен, поскольку на первый взгляд сулит существенную экономию, так как число дней в году умножается на число товаров и продавцов. Однако если данные о продажах являются разреженными, то есть не каждый товар продается ежедневно, то экономия может оказаться весьма незначительной.
Выбор нужных агрегатов всегда определяется особенностями бизнеса. При этом следует помнить, что агрегаты, требуемые для анализа, могут быть вычислены и непосредственно при выполнении аналитического запроса к ХД, хотя тем самым время его выполнения несколько увеличится. Подобный подход позволяет, например, отказаться от агрегирования редко используемых данных.
Таким образом, выбор правильной стратегии агрегирования данных в ETL — сложная и противоречивая задача. Увеличение числа агрегатов в ХД приводит к увеличению его размеров и сложности структуры данных. Снижение числа агрегатов в ХД может привести к необходимости их вычисления в процессе выполнения аналитических запросов, что увеличит время ожидания пользователя. Следовательно, необходимо обеспечить разумный компромисс между этими факторами. Существует и более простое правило, определяющее стратегию агрегирования: создавайте только те агрегаты, которые с большой долей вероятности понадобятся при анализе данных.
Перевод значений
Часто данные в источниках хранятся с использованием специальных кодировок, которые позволяют сократить избыточность данных и тем самым уменьшить объем памяти, требуемой для их хранения. Так, наименования объектов, их свойств и признаков могут храниться в сокращенном виде. В этом случае перед загрузкой данных в хранилище требуется выполнить перевод таких сокращенных значений в более полные и, соответственно, понятные.
Например, согласно заведенному в организации порядку идентификационный номер операции может быть закодирован в виде 06–04–12–62, где 06–04 — число и месяц, 12 — код товара, 62 — код региона. Такое представление позволяет хранить данные очень компактно. Однако для заполнения соответствующих измерений в многомерной модели запись необходимо декодировать.
Кроме того, часто возникает необходимость конвертировать числовые данные, например преобразовать вещественные в целые, уменьшить избыточную точность представления чисел, использовать экспоненциальный формат и т.д.
Создание новых данных
В процессе загрузки в ХД может понадобиться вычисление некоторых новых данных на основе существующих, что обычно сопровождается созданием новых полей. Например, OLTP-система содержит информацию только о количестве и цене проданного товара, а в целевой таблице ХД есть поле Сумма. Тогда в процессе преобразования необходимо вычислить сумму как произведение цены на количество проданных единиц товара. Таким образом, будет создано поле, содержащее новую информацию.
Еще одним возможным примером новых данных, создаваемых в процессе обработки, являются экономические, финансовые и другие показатели, которые могут быть вычислены на основе имеющихся данных. Так, на основе данных о продажах можно рассчитать рейтинг популярности товаров и создать новое поле, в котором для каждого товара будет указано соответствующее рейтинговое значение (например, по пятибалльной системе).
Создание новой информации на основе имеющихся данных тесно связано с таким важным процессом, как обогащение данных, которое может производиться (частично или полностью) на этапе преобразования данных в ETL. Агрегирование также может рассматриваться как создание новых данных.
Очистка данных
Сбор данных в процессе ETL производится из большого числа источников, многие из которых не содержат автоматических средств поддержки целостности, непротиворечивости и корректного представления данных. В связи с этим при переносе информации в ХД приходится сталкиваться с потоками «грязных» данных, которые могут стать причиной неправильных результатов анализа и даже сделать невозможным применение некоторых аналитических алгоритмов и методов. По этой причине в процессе ETL применяется очистка — процедура корректировки данных, которые в каком-либо смысле не удовлетворяют определенным критериям качества, то есть содержат нарушения структуры данных, противоречия, пропуски, дубликаты, неправильные форматы и т.д.
Некоторые проблемы в данных являются критичными и даже не позволяют выполнить загрузку данных в ХД (как правило, это нарушения структуры и некорректные форматы данных). Другие проблемы менее критичны, не мешают переносу данных в ХД, но не позволяют их корректно анализировать (пропуски, противоречия и дубликаты). Критичные проблемы в данных должны устраняться непосредственно в процессе ETL. Некритичные факторы, снижающие качество данных, могут устраняться как в процессе ETL, так и при подготовке их к анализу в аналитической системе.
Очистка данных — одна из наиболее важных и в то же время наиболее сложных и трудно поддающихся формализации задач ETL-процесса, поскольку набор факторов, снижающих качество данных, весьма разнообразен и может постоянно меняться. Поэтому очистке данных при разработке ETL-процессов уделяют большое внимание.
Выбор места для выполнения преобразований данных
В принципе, преобразование данных может быть выполнено на любом этапе ETL-процесса. Но иногда требуется выбрать оптимальное место для осуществления преобразования. Некоторые виды преобразований удобнее выполнять «на лету», в процессе извлечения данных из источника, другие — в промежуточной области, третьи — в процессе загрузки данных в ХД. Рассмотрим преимущества и недостатки этих вариантов.
Преобразование в процессе извлечения данных. На данном этапе лучше всего выполнять преобразование типов данных и производить фильтрацию записей, представляющих интерес для ХД. В идеальном случае должны отбираться только те записи, которые изменялись или создавались после прошлой загрузки. Недостаток — повышение нагрузки на OLTP-систему или БД.
Преобразование в промежуточной области перед загрузкой данных в хранилище — наилучший вариант для интеграции данных из множества источников, поскольку в процессе извлечения данных, очевидно, этого сделать нельзя. В промежуточной области целесообразно выполнять такие виды преобразований, как сортировка, группировка, обработка временных рядов и т.п.
Преобразование в процессе загрузки данных в ХД. Отдельные простые преобразования, например преобразование регистров букв в текстовых полях, могут быть выполнены только после загрузки данных в хранилище.
Таким образом, все операции преобразования, которые могут потребоваться при переносе данных в ХД, обычно не сосредотачиваются на одном шаге ETL-процесса, а распределяются по различным этапам в зависимости от того, где выполнение преобразования более эффективно.
Загрузка данных в хранилище
После того как данные извлечены из различных источников и выполнены преобразование, агрегация и очистка данных, осуществляется последний этап ETL — загрузка данных в хранилище. Процесс загрузки заключается в переносе данных из промежуточных таблиц в структуры хранилища данных. От продуманности и оптимальности процесса загрузки данных во многом зависит время, требуемое для полного цикла обновления данных в ХД, а также полнота и корректность данных в хранилище.
Организация процесса загрузки
Первыми в процессе загрузки данных в ХД обычно загружаются таблицы измерений, которые содержат суррогатные ключи и другую описательную информацию, необходимую для таблиц фактов.
При загрузке таблиц измерений требуется и добавлять новые записи, и изменять существующие. Например, измерение Клиент может содержать десятки тысяч клиентов, при этом информация меняется только для незначительного их числа (не более 10%). Нужно добавить данные о новых клиентах и одновременно модифицировать информацию о существующих.
При добавлении новых данных в таблицу измерений требуется определить, не существует ли в ней соответствующая запись. Если нет, то она добавляется в таблицу. В противном случае могут использоваться различные способы обработки изменений в зависимости от того, нужно ли поддерживать старую информацию в хранилище с целью ее последующего анализа. Например, если изменился только адрес клиента, то в большинстве случаев нет необходимости хранить старый адрес, поэтому запись может быть просто обновлена.
У быстро растущих компаний часто возникают новые регионы продаж. Например, если сначала регионом продаж была только Рязанская область, то впоследствии он может расшириться на весь Центральный федеральный округ (ЦФО) и далее на всю Российскую Федерацию. Если в ХД требуется хранить как старую географическую иерархию, так и обновленную, можно создать дополнительную таблицу измерений, записи которой будут содержать и старые географические данные, и новые. В качестве альтернативы можно добавить дополнительные поля в существующие таблицы, чтобы сохранить старую информацию и добавить новую.
При загрузке таблицы фактов новая информация обычно добавляется в конец таблицы, чтобы не изменять существующие данные.
Неполная загрузка данных
Одной из основных проблем данного этапа ETL является то, что далеко не всегда данные загружаются полностью: в загрузке некоторых записей может быть отказано. Отклонение записей происходит по следующим причинам.
На этапе преобразования данных не удалось исправить все критичные ошибки, которые блокируют загрузку записей в ХД.
Некорректный порядок загрузки данных. Например, предпринимается попытка загрузить факты для значения измерения, которое еще не было загружено. Причиной этого является неправильная разработка ETL-процесса.
Внутренние проблемы ХД, например недостаток места в нем.
Прерывание процесса загрузки или остановка его пользователем. Независимо от причин результатом всегда оказывается наличие определенного количества записей, которые не попали в хранилище. Как правило, предусмотрена система извещения пользователя о том, что хранилище содержит не полностью загруженные данные. Это необходимо потому, что если неполные данные будут использованы для анализа (при этом аналитик пребывает в уверенности, что данные достоверны), то последствия могут быть непредсказуемыми. Например, если не до конца загрузились данные о продажах по определенным товарным позициям и последующий анализ выявит падение продаж, то руководство компании может ошибочно исключить такие товары из ассортимента как не пользующиеся спросом, хотя на самом деле это не так.
При появлении данных, попытка загрузки которых потерпела неудачу, необходимо предусмотреть следующие действия :
сохранить данные, не попавшие в ХД, в виде таблицы или файла того же формата, что и исходная таблица или файл (такие таблицы обычно называют таблицами исключений);
провести анализ отклоненных данных для выявления причин, по которым они не были загружены;
при необходимости произвести дополнительную обработку и очистку данных, после чего предпринять повторную попытку их загрузки.
Если и повторная попытка загрузки данных не увенчалась успехом, то в хранилище окажутся неполные данные, анализ которых может привести к неправильным выводам. Для решения этой проблемы можно:
восстановить состояние хранилища, каким оно было до загрузки (например, с помощью резервной копии или операции отката, если она предусмотрена);
полностью очистить в ХД таблицы с неполными данными, чтобы исключить некорректные результаты их анализа;
оставить все как есть и уведомить пользователя о возникших проблемах. В этом случае аналитик узнает, что загруженная информация недостоверна, и будет использовать ее с определенными ограничениями.
Многопоточная организация процесса загрузки данных
При очередной загрузке в ХД переносится не вся информация из OLTP-системы, а только та, которая была изменена в течение промежутка времени, прошедшего с предыдущей загрузки. При этом можно выделить два вида изменений — добавление и обновление (дополнение).
Добавление — в ХД передается новая, ранее не существовавшая информация, например сведения о продажах, произошедших с прошлой загрузки, о появлении нового клиента, товара и т.д.
Обновление (дополнение) — в ХД передается информация, которая существовала ранее, но по какой-либо причине была изменена или дополнена (например, изменился город, в котором живет клиент).
Для обеспечения этих функций загружаемые данные распределяются по двум параллельным потокам (data flow) — потоку добавления и потоку обновления.
Для распределения загружаемых данных на потоки используются средства мониторинга изменений в данных. Они фиксируют состояние данных в некоторые моменты времени и определяют, какие данные были изменены или дополнены. Применяются следующие методы:
полное сравнение загружаемых записей со всей информацией, которая уже содержится в хранилище. Данный способ является самым простым и в то же время самым трудоемким в плане вычислительных затрат;
использование признаков модифицированных данных или полей Дата/Время для определения последнего изменения записи (если такие поля предусмотрены в источнике данных).
Распределение загружаемых данных на поток добавления и поток обновления позволяет выполнять перенос данных в хранилище с помощью обычных запросов, не используя какие-либо фильтры для разделения данных на новые и обновляющие.
Обновление данных должно производиться строго в соответствии с требованиями к обеспечению истории данных, то есть не должно приводить к потере уже существующих данных, за исключением особых случаев.
Следует отметить, что при разработке методики загрузки данных в ХД нет общего подхода к тому, как модифицировать таблицы измерений. Например, если изменилось описание некоторого продукта, придется создать новое поле в таблице, чтобы сохранить старое описание и добавить новое. Если требуется сохранить все старые описания продукта, то придется создавать новую запись для каждого изменения и назначать соответствующие ключи.
Постзагрузочные операции
После завершения загрузки выполняются дополнительные операции над данными, только что загруженными в ХД, перед тем как сделать их доступными для пользователя. Такие операции называются постзагрузочными. К ним относятся переиндексация, верификация данных и т.д.
С точки зрения аналитика, наиболее важной задачей является верификация данных. Прежде чем использовать новые данные для анализа, полезно убедиться в их надежности и достоверности. Для этих целей можно предусмотреть комплекс верификационных тестов. Например:
при суммировании продаж по одному измерению результат должен совпадать с соответствующей суммой, полученной по другому, связанному с ним измерению, то есть сумма продаж по всем товарам за месяц должна соответствовать сумме сделок, заключенных со всеми клиентами за тот же период;
итоговый показатель за месяц должен соответствовать сумме ежедневных или еженедельных показателей в этом месяце;
суммарная выручка по всем регионам за текущий месяц должна соответствовать сумме продаж по всем региональным дилерским центрам.
Кроме того, может оказаться полезным сравнивать данные не только в различных разрезах после их загрузки в ХД, но и с источниками данных. Так, если значения какого-либо показателя в источнике и хранилище равны, то все нормально, в противном случае данные, возможно, некорректны.
Если тестирование показало, что несоответствия, позволяющие заподозрить потерю или недостоверность данных, отсутствуют, то можно считать загрузку данных в ХД успешной и приступать к анализу новой информации.
Загрузка данных из локальных источников
Довольно часто возникают ситуации, когда данные для анализа приходится импортировать непосредственно из источников, минуя хранилища данных и другие промежуточные системы. Это может потребоваться в случае, когда организация отказалась от использования ХД или когда хранилище имеется, но данные из некоторых источников не могут быть в него загружены по техническим причинам, из-за несоответствия моделям и форматам данных, используемым в ХД.
Таким образом, часть данных поступает в аналитическую систему через ХД с соответствующей очисткой и подготовкой, а другая часть — непосредственно из источников .
Извлечение данных напрямую из источников имеет свои преимущества и недостатки, а также порождает ряд проблем, связанных как непосредственно с процессом извлечения, так и с качеством полученных данных.
Преимущества и недостатки отказа от хранилищ данных
Главным преимуществом, которое дает использование хранилищ данных в аналитических технологиях, является повышение эффективности и достоверности анализа данных, особенно для поддержки принятия стратегических решений. Это достигается за счет оптимизации скорости доступа к данным, возможности интеграции данных различных форматов и типов, автоматической поддержки целостности и непротиворечивости, обеспечения хронологии и истории данных.
Тем не менее некоторые организации не используют хранилища данных для консолидации анализируемой информации. При необходимости выполнения анализа данные загружаются в аналитическое приложение непосредственно из источников, где они содержатся, а семантический слой обеспечивается средствами самого аналитического приложения.
Причины отказа от использования ХД могут быть следующими.
1. Организация не располагает достаточными ресурсами (финансовыми, техническими, кадровыми) для разработки, приобретения и поддержки ХД.
2. Унаследованная система аналитической обработки эффективно функционирует с использованием обычной реляционной СУБД, и руководство не видит смысла в дорогостоящем и трудоемком процессе внедрения ХД.
3. Объем анализируемых данных невелик, а применяемые технологии анализа данных несложны. В частности, не требуется поддержка хронологии данных, для анализа используются только данные за актуальный период и т.д.
4. Роль анализа в деятельности организации невысока, администрация не осознала его значимость в получении конкурентных преимуществ.
Таким образом, причин для отказа от использования ХД в аналитическом процессе достаточно много и все они могут быть по-своему аргументированы. В некоторых случаях отказ от ХД дает определенные преимущества: аналитический процесс становится проще и дешевле; нет необходимости разрабатывать концепцию его внедрения; не нужны сложный процесс ETL и другие сопутствующие затраты. Кроме того, процессы, связанные с поддержкой ХД, — интегрирование данных из различных источников и ETL, — если они недостаточно продуманы и некачественно реализованы, способны не только свести на нет все преимущества, которые дает ХД, но и ухудшить ситуацию, породив массу ошибок и проблем с получением данных. Возможно также, что лучше быстро реализовать аналитический процесс в упрощенном варианте, чем годами отлаживать взаимодействие OLTP-систем с ХД.
Проблемы, возникающие при прямом доступе к источникам данных
Отказ от использования ХД для консолидации и интегрирования данных не только снижает эффективность анализа, достоверность и значимость его результата, но и порождает ряд дополнительных проблем как технического, так и методического плана. Конечно, они присутствуют и при использовании ХД, но в этом случае они автоматически решаются самим хранилищем и поддерживающими его программными средствами. При осуществлении прямого доступа к источникам данных пользователь (эксперт, аналитик) вынужден сталкиваться с этими проблемами непосредственно. К таким проблемам относятся следующие.
Необходимость самостоятельно определять тип и формат источника данных. Узнать тип и формат файла можно по его расширению. Однако, если приходится иметь дело с экзотическим форматом или типом файла, этот вопрос может потребовать дополнительного исследования. Например, если речь идет о текстовом файле с разделителями, то TXT-формат известен любому, кто работал на компьютере, поскольку его освоение обычно начинается с создания простейших текстовых файлов. В то же время формат CSV в повседневной работе используется достаточно редко и поэтому большинству пользователей неизвестен. Кроме того, при загрузке данных из СУБД пользователь сталкивается с поиском нужной таблицы, что само по себе не очень сложно, но может занять определенное время.
Отсутствие полноценного семантического слоя того уровня, который имеется в ХД. При работе с ХД, которое обеспечивает семантический слой, преобразующий высокоуровневые запросы пользователей в низкоуровневые запросы к источникам данных, пользователь оперирует такими бизнес-терминами предметной области, как наименования товаров и клиентов, цена, количество, сумма, наценка, скидка и т.д. При работе с источниками данных напрямую аналитик вынужден иметь дело непосредственно с именами полей источника, которые в большинстве случаев вводятся на латинице и не всегда понятны, поэтому приходится тратить время на то, чтобы разобраться, в каком поле содержатся нужные данные.
Отсутствие жесткой поддержки структуры и форматов данных. При непосредственной работе с источниками данных часто приходится иметь дело с файлами, в которых структура и формат данных жестко не заданы. Типичный пример — текстовый файл с разделителями, в котором данные упорядочены в столбцы, отделенные друг от друга однотипными символами-разделителями. В таких файлах могут быть любые нарушения структуры и форматов данных. В них могут содержаться неполные поля и записи, использоваться различные символы — разделители столбцов, произвольные разделители целой и дробной частей и групп разрядов в числах. В одном и том же столбце могут оказаться и строковые, и числовые данные, различные форматы даты и т.д. Особенно это характерно для файлов, которые создавались без учета перспективы анализа данных. В подобной ситуации ничего не остается, кроме как попытаться выполнить корректировку данных средствами, имеющимися в аналитическом приложении. Иногда структура данных в файле оказывается настолько искаженной, что его загрузка в аналитическую систему невозможна. Тогда редактировать данные приходится непосредственно в источнике. И в том и в другом случае ручная корректировка данных является очень трудоемкой и затратной по времени. Если затраты на подготовку данных превышают их ценность с точки зрения анализа, то, возможно, от работы с ними следует вообще отказаться.
Отсутствие автоматических средств поддержки целостности, непротиворечивости и уникальности данных. Эта проблема главным образом возникает при работе с локальными файлами. При извлечении данных может произойти разрыв связей между атрибутами и, как следствие, потеря целостности данных.
Отсутствие средств автоматического агрегирования и создания новых данных. При использовании ХД предусмотрены автоматические агрегирование данных и расчет вычисляемых значений (обычно в процессе ETL). Эти новые данные сохраняются и остаются доступными в любой момент, что ускоряет выполнение аналитических запросов. Когда загрузка данных производится напрямую из источников, агрегирование и вычисление новых данных приходится делать непосредственно в ходе выполнения запросов либо вручную, что существенно снижает скорость работы.
Отсутствие средств автоматического контроля ошибок и очистки данных. Это приводит к тому, что в аналитическую систему загружаются «грязные» данные, зачастую непригодные для анализа, поэтому пользователь должен самостоятельно (визуально и с помощью статистических характеристик или специальных средств, если они доступны) оценить качество данных, степень их пригодности для анализа и применить необходимые методы очистки.
Необходимость настройки механизмов доступа к источникам данных. Для осуществления непосредственного доступа к различным источникам данных обычно используются стандартные механизмы доступа — ODBC, ADO и OLE DB. Чтобы указанные компоненты функционировали правильно, они должны быть соответствующим образом настроены, что также зачастую ложится на плечи пользователя или системного администратора.
Преимущества использования непосредственного доступа к источникам данных
Помимо недостатков, использование непосредственного доступа к источникам данных имеет ряд преимуществ.
Отсутствие ETL-процесса снимает проблему «окна загрузки», то есть промежутка времени, в течение которого производятся загрузка ХД и сопутствующие ей операции. Обычно во время «окна загрузки» нагрузка на систему предприятия резко возрастает, а производительность работы пользователей, наоборот, падает, при этом само ХД может оказаться частично или полностью недоступным.
Возможность внерегламентного использования источников данных. Обычно обновление данных в хранилище производится в соответствии с определенным регламентом. Это в некоторой степени связывает руки пользователю. Например, если загрузка новой информации в ХД осуществляется раз в неделю, а непосредственный доступ к источникам данных не предусмотрен, то пользователю приходится ждать, пока данные не появятся в ХД и не станут доступными.
Возможность получать для анализа данные, которые почему-либо не попали в хранилище (например, по техническим причинам как не представляющие ценности). Кроме того, у сотрудников организаций часто накапливаются данные, собранные ими для собственного использования. На первый взгляд такие данные кажутся свалкой информационного мусора (чем чаще всего и являются), поскольку при их сборе и организации используются нестандартные методы, отличные от тех, которые применяются при сборе и консолидации данных через хранилище. Однако именно благодаря этому на основе таких данных можно получить очень интересные и нестандартные аналитические решения.
Пользователь имеет возможность работать с данными в их «первозданном» виде, что представляет особый интерес, поскольку при загрузке данных в ХД в них вносятся изменения, которые в некоторых случаях влияют на их изначальный смысл.
Таким образом, необходимость в организации непосредственного доступа к различным источникам данных из аналитического приложения возникает даже при наличии ХД.
Особенности непосредственной загрузки данных из наиболее распространенных типов источников
Наиболее часто встречающимися видами источников данных, доступ к которым производится напрямую, являются:
текстовые файлы с разделителями (TXT, CSV);
файлы электронных таблиц Excel;
файлы плоских таблиц БД, например dBase, FoxPro и т.д. (DBF-файлы);
реляционные СУБД настольного уровня, например Access и т.д.;
корпоративные базы данных и учетные системы (Oracle, Informix, Sybase, DB2 и т.д.).
Текстовые файлы с разделителями (TXT, CSV). Файлы в TXT-формате хорошо известны большинству пользователей (даже непрофессиональных) еще со времен MS-DOS. Для создания таких файлов достаточно использовать простейший текстовый редактор, например Блокнот из набора стандартных программ Windows. Однако эти файлы имеют произвольную структуру данных, поэтому они наиболее уязвимы с точки зрения нарушения структуры, использования некорректных форматов и представлений данных. Так что загрузка и очистка TXT-файлов могут вызвать самые серьезные проблемы, несмотря на то что эти файлы очень просты в создании.
Чтобы создать структурированный текстовый файл, который может быть загружен в аналитическую систему, достаточно упорядочить в нем данные в виде вертикальных столбцов и горизонтальных строк, из которых будут сформированы поля и записи соответственно. Для разделения столбцов должны использоваться однотипные символы-разделители, например табуляция, точка с запятой и др. Можно использовать как один символ, так и несколько идущих подряд символов. При создании файла следует придерживаться нескольких правил.
В первой строке файла нужно указать заголовки столбцов в произвольной форме, при этом используются кириллица и пробелы. При загрузке в аналитическую систему заголовки столбцов будут преобразованы в метки полей, что позволит аналитику быстрее разобраться с содержимым источника. Поскольку в TXT-файлах имена полей (в том виде, как они представлены в таблицах файлов БД) отсутствуют, при загрузке в аналитическую систему они будут установлены автоматически в соответствии с правилами, принятыми в данной системе. Например, им по умолчанию могут быть присвоены метки COL1, COL2 или FIELD1, FIELD2 и т.д. Если в первой строке текстового файла над каждым столбцом указано его название, то система при загрузке сможет преобразовать эти названия в имена полей, если каким-либо образом указать, что первая строка содержит заголовки. Однако это возможно только при условии, что названия столбцов не противоречат правилам назначения имен полей в данной аналитической системе, то есть не содержат недопустимых символов, не превышают заданную длину и т.д. Это следует учитывать при создании текстовых файлов с разделителями, которые планируется использовать в качестве источников данных для аналитических систем.
Необходимо соблюдать регулярность структуры данных, то есть каждые строка и столбец должны содержать одинаковое число элементов. Если некоторые значения были утеряны, то их можно заменить средними значениями по столбцу для числовых атрибутов. Для строковых атрибутов можно указать наиболее вероятное значение или значение по умолчанию, которое впоследствии может быть соответствующим образом обработано (например, NONAME). Оставлять пустые или фиктивные значения нежелательно: пропущенное значение может заблокировать работу аналитических алгоритмов, а фиктивное (например, $999,999) может быть обработано как истинное.
Столбцы должны быть типизированы, то есть содержать данные только одного типа (например, только строковые или только числовые). Кроме того, внутри каждого столбца формат представления чисел или дат должен быть одинаковым. Например, использование в одном столбце краткого (12.07.06) и полного (12 июля 2006 г.) форматов даты способно вызвать серьезные проблемы при загрузке данных. Также нежелательно использовать в одном поле числа в экспоненциальном формате (1,2E + 3) и в обычном (12 000), поскольку это может вызвать проблемы при загрузке значений из данного поля.
Строковые значения желательно приводить в соответствие унифицированным шаблонам. Например, нежелательно смешивать представление ФИО, указывая инициалы то справа, то слева от фамилии или вообще не указывая, использовать в инициалах то одну, то две буквы и т.д. При указании названий организаций также нужно использовать единое представление. Например, форма собственности должна во всех строках указываться только после названия (это упростит сортировку названий по алфавиту). Несоблюдение этого требования, скорее всего, не вызовет проблем при загрузке, но может привести к неправильной обработке таких данных аналитическим приложением.
Символы-разделители и их количество во всех строках и между столбцами должны быть одинаковыми.
Необходимо использовать одинаковые разделители целой и дробной частей чисел и групп разрядов. Например, если по умолчанию в качестве разделителя целой и дробной частей используется точка, а в каком-то значении будет обнаружена запятая, это значение будет рассматриваться системой как строковое.
При загрузке в ХД все эти проблемы автоматически корректируются на этапе ETL. А при непосредственной загрузке пользователю приходится отслеживать эти проблемы самому. Если данных в источнике немного, то они могут быть откорректированы вручную. В противном случае приходится использовать средства очистки данных, предусмотренные в аналитической системе (например, восстановление пропущенных значений, трансформация типов и т.д.).
Чтобы настроить процесс импорта текстового файла с разделителями, обычно требуется указать:
имя файла и путь к нему;
символ-разделитель, используемый для разделения столбцов;
используемый формат даты (времени);
используемые разделители целой и дробной частей чисел и групп разрядов;
номер строки файла, с которой требуется начать извлечение данных (если все данные извлекать не нужно или нужно извлечь только те данные, которыми файл был пополнен с прошлой загрузки);
является ли первая строка строкой заголовков. Если да, то содержимое первой строки будет преобразовано в метки полей, а данные начнут загружаться со второй строки.
Таким образом, чтобы правильно настроить параметры импорта текстового файла, нужно иметь информацию о файле, которая в большинстве случаев может быть получена только опытным путем. Для этого достаточно открыть файл с помощью текстового редактора, просмотреть структуру файла и при необходимости откорректировать ее (например, присвоить столбцам заголовки).
Текстовые файлы в формате CSV менее известны пользователям, поскольку используются реже, чем обычные TXT-файлы. CSV (от англ. comma separated values — «значения, разделенные запятыми») — это специальный текстовый формат, предназначенный для представления табличных данных. Каждая строка в таком файле соответствует одной строке таблицы. Значения отдельных столбцов разделяются специальным символом — запятой или точкой с запятой. Используемый символ-разделитель зависит от настроек региональных стандартов. В США это запятая, а в России — точка с запятой, поскольку у нас запятая используется для разделения целой и дробной частей чисел (в отличие от США, где для этого служит точка). Файлы такого типа могут быть получены путем конвертации из любого табличного процессора.
Все свойства обычных текстовых файлов с разделителями, описанные выше, и рекомендации по их подготовке и загрузке в полной мере относятся к CSV-файлам. Но у CSV-файлов есть и ряд преимуществ.
Использование унифицированного символа-разделителя (запятой) позволяет избежать разночтений и связанных с этим проблем.
Поскольку CSV-файлы в большинстве случаев являются результатом преобразования файлов Excel, в них более жестко задана структура строк и столбцов.
Файлы «плоских» таблиц СУБД семейства dBase, FoxBase, FoxPro и т.д. имеют расширение DBF (database file). Как и файлы любых СУБД, DBF-файлы имеют жестко заданную структуру. В них строго определены имена и типы полей, структура полей и записей, используемые форматы представления данных. Следовательно, проблем с загрузкой данных из таких источников намного меньше по сравнению с текстовыми файлами, поскольку все возможные проблемы контролируются в процессе создания файла. СУБД не позволит присвоить полю некорректное имя, ввести в поле данные, не соответствующие его типу или использующие неправильный разделитель групп разрядов в числе, и т.д., поэтому ожидаемое качество данных, загружаемых из DBF-файлов, является более высоким, чем для текстовых.
При загрузке данных из DBF-файлов в аналитическую систему, как правило, достаточно указать их имя. В некоторых случаях требуется дополнительно указать версию СУБД (dBase III или dBase IV), а также кодовую страницу для корректного отображения символов.
Excel — одно из наиболее популярных офисных приложений, применяемых пользователями всех уровней, поэтому возможность загрузки данных из файлов в формате XLS предусмотрена практически в любой аналитической системе. Однако следует учитывать, что в одном столбце таблицы Excel могут содержаться данные различных типов и форматов, допускаться неправильное использование разделителей целой и дробной частей чисел и групп разрядов в них. В этом плане к ним следует относиться так же внимательно, как и к данным из текстовых файлов.
Файлы реляционных СУБД. Источники этого типа самые «желанные» для пользователей аналитических систем, поскольку с ними меньше всего проблем. Структура данных в файлах реляционных СУБД жестко задана, поля строго типизированы, форматы данных соответствуют стандартам. В большинстве СУБД поддерживается автоматический контроль целостности, непротиворечивости и уникальности данных. Для загрузки данных, например, из файла Access достаточно указать имя файла и таблицу, из которой нужно взять данные.
Бизнес-анализ информации
Бизнес-анализ, это набор задач и техник, используемых как связующее между участниками и заинтересованными лицами для понимания структуры, правил и операций в рамках организации, так и для рекомендации решений, позволяющих данной организации достичь ее целей. Бизнес-анализ предусматривает понимание, как функционируют организации, чтобы соответствовать их назначению и определение возможностей, которые требуются организации для предоставления продуктов и услуг внешним (по отношению к организации) заинтересованным лицам. Он (бизнес-анализ) включает в себя указание целей организации, связей этих целей с отдельными задачами, определение направления действий организации для достижения указанных целей и задач, а также задание способов (процессов), как различные подразделения и заинтересованные лица в самой организации и за ее рамками будут взаимодействовать между собой.
ается мысль, мы не в состоянии, сконцентрируемся на том, как можно в этом процессе использовать информационные технологии. Первый вариант – лицо, принимающее решение (ЛПР), использует компьютер только как средство извлечения данных, а выводы делает уже самостоятельно. Для решения такого рода задач используются системы отчетности, многомерный анализ данных, диаграммы и прочие способы визуализации. Второй вариант: программа не только извлекает данные, но и проводит различного рода предобработку, например, очистку, сглаживание и прочее. А к обработанным таким образом данным применяет математические методы анализа – кластеризацию, классификацию, регрессию и т.д. В этом случае ЛПР получает не сырые, а прошедшие серьезную обработку данные, т.е. человек уже работает с моделями, подготовленными компьютером.
Благодаря тому, что в первом случае практически все, что связано собственно с механизмами принятия решений, возлагается на человека, проблема с подбором адекватной модели и выбором методов обработки выносится за пределы механизмов анализа, т. е. базой для принятия решения является либо инструкция (например, каким образом можно реализовать механизмы реагирования на отклонения), либо интуиция. В некоторых случаях этого вполне достаточно, но если ЛПР интересуют знания, находящиеся достаточно глубоко, если так можно выразиться, то просто механизмы извлечения данных тут не помогут. Необходима более серьезная обработка. Это и есть тот самый второй случай. Все применяемые механизмы предобработки и анализа позволяют ЛПР работать на более высоком уровне. Первый вариант подходит для решения тактических и оперативных задач, а второй – для тиражирования знаний и решения стратегических проблем. Идеальным случаем была бы возможность применять оба подхода к анализу. Они позволяют покрыть почти все потребности организации в анализе бизнес информации. Варьируя методики в зависимости от задач, мы будем иметь возможность в любом случае выжать максимум из имеющейся информации.
Общая схема работы приведена ниже.
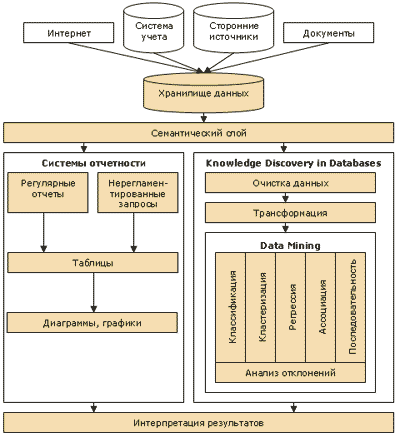
Часто при описании того или иного продукта, анализирующего бизнес информацию, применяют термины типа риск-менеджмент, прогнозирование, сегментация рынка… Но в действительности решения каждой из этих задач сводятся к применению одного из описанных ниже методов анализа. Например, прогнозирование – это задача регрессии, сегментация рынка – это кластеризация, управление рисками – это комбинация кластеризации и классификации, возможны и другие методы. Поэтому данный набор технологий позволяет решать большинство бизнес задач. Фактически, они являются атомарными (базовыми) элементами, из которых собирается решение той или иной задачи.
В качестве первичного источника данных должны выступать базы данных систем управления предприятием, офисные документы, Интернет, потому что необходимо использовать все сведения, которые могут пригодиться для принятия решения. Причем речь идет не только о внутренней для организации информации, но и о внешних данных (макроэкономические показатели, конкурентная среда, демографические данные и т.п.).
Хотя в хранилище данных не реализуются технологии анализа, оно является той базой, на которой нужно строить аналитическую систему. В отсутствие хранилища данных на сбор и систематизацию необходимой для анализа информации будет уходить большая часть времени, что в значительной степени сведет на нет все достоинства анализа. Ведь одним из ключевых показателей любой аналитической системы является возможность быстро получить результат.
Следующим элементом схемы является семантический слой. Вне зависимости от того, каким образом будет анализироваться информация, необходимо, чтобы она была понятна ЛПР, поскольку в большинстве случаев анализируемые данных располагаются в различных базах данных, а ЛПР не должен вникать в нюансы работы с СУБД, то требуется создать некий механизм, трансформирующий термины предметной области в вызовы механизмов доступа к БД. Эту задачу и выполняет семантический слой. Желательно, чтобы он был один для всех приложений анализа, таким образом легче применять к задаче различные подходы.
Системы отчетности предназначены для того, чтобы дать ответ на вопрос “что происходит”. Первый вариант его использования: регулярные отчеты используются для контроля оперативной ситуации и анализа отклонений. Например, система ежедневно готовит отчеты об остатках продукции на складе, и когда его значение меньше средней недельной продажи, необходимо реагировать на это подготовкой заказа на поставку, т. е. в большинстве случаев это стандартизированные бизнес операции. Чаще всего некоторые элементы этого подхода в том или ином виде реализованы в компаниях (пусть даже просто на бумаге), однако нельзя допускать, чтобы это был единственный из доступных подходов к анализу данных. Второй вариант применения систем отчетности: обработка нерегламентированных запросов. Когда ЛПР хочет проверить какую-либо мысль (гипотезу), ему необходимо получить пищу для размышлений подтверждающую либо опровергающую идею, т. к. эти мысли приходят спонтанно, и отсутствует точное представление о том, какого рода информация потребуется, необходим инструмент, позволяющий быстро и в удобном виде эту информацию получить. Извлеченные данные обычно представляются либо в виде таблиц, либо в виде графиков и диаграмм, хотя возможны и другие представления.
Хотя для построения систем отчетности можно применять различные подходы, самый распространенный на сегодня – это механизм OLAP. Основной идеей является представление информации в виде многомерных кубов, где оси представляют собой измерения (например, время, продукты, клиенты), а в ячейках помещаются показатели (например, сумма продаж, средняя цена закупки). Пользователь манипулирует измерениями и получает информацию в нужном разрезе.
Благодаря простоте понимания OLAP получил широкое распространение в качестве механизма анализа данных, но необходимо понимать, что его возможности в области более глубокого анализа, например, прогнозирования, крайне ограничены. Основной проблемой при решении, задач прогнозирования является вовсе не возможность извлечения интересующих данных в виде таблиц и диаграмм, а построение адекватной модели. Дальше все достаточно просто. На вход имеющейся модели подается новая информация, пропускается через нее, а результат и есть прогноз. Но построение модели является совершенно нетривиальной задачей. Конечно, можно заложить в систему несколько готовых и простых моделей, например, линейную регрессию или что-то аналогичное, довольно часто именно так и поступают, но это проблему не решает. Реальные задачи почти всегда выходят за рамки таких простых моделей. А следовательно, такая модель будет обнаруживать только явные зависимости, ценность обнаружения которых незначительна, что и так хорошо известно и так, или будут строить слишком грубые прогнозы, что тоже совершенно неинтересно. Например, если вы будете при анализе курса акций на фондовом рынке исходить из простого предположения, что завтра акции будут стоить столько же, сколько и сегодня, то в 90% случаев вы угадаете. И насколько ценны такие знания? Интерес для брокеров представляют только оставшиеся 10%. Примитивные модели в большинстве случаев дают результат примерно того же уровня.
Правильным подходом к построению моделей является их пошаговое улучшение. Начав с первой, относительно грубой модели, необходимо по мере накопления новых данных и применения модели на практике улучшать ее. Собственно задача построения прогнозов и тому подобные вещи выходят за рамки механизмов систем отчетности, поэтому и не стоит ждать в этом направлении положительных результатов при применении OLAP. Для решения задач более глубокого анализа применяется совершенно другой набор технологий, объединенных под названием Knowledge Discovery in Databases .
Knowledge Discovery in Databases (KDD) – это процесс преобразования данных в знания. KDD включает в себя вопросы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining (DM), постобработки данных, интерпретации полученных результатов.
Привлекательность этого подхода заключается в том, что вне зависимости от предметной области мы применяем одни и те же операции:
Извлечь данные. В нашем случае для этого нужен семантический слой.
Очистить данные. Применение для анализа “грязных” данных может полностью свести на нет применяемые в дальнейшем механизмы анализа.
Трансформировать данные. Различные методы анализа требуют данных, подготовленных в специальном виде. Например, где-то в качестве входов может использоваться только цифровая информация.
Провести, собственно, анализ – Data Mining.
Интерпретировать полученные результаты.
Интерпретация результатов компьютерной обработки возлагается на человека. Просто различные методы дают различную пищу для размышлений. В самом простом случае – это таблицы и диаграммы, а в более сложном – модели и правила. Полностью исключить участие человека невозможно, т.к. тот или иной результат не имеет никакого значения, пока не будет применен к конкретной предметной области. Однако имеется возможность тиражировать знания. Например, ЛПР при помощи какого-либо метода определил, какие показатели влияют на кредитоспособность покупателей, и представил это в виде правила. Правило можно внести в систему выдачи кредитов и таким образом значительно снизить кредитные риски, поставив их оценки на поток. При этом от человека, занимающегося собственно выпиской документов, не требуется глубокого понимания причин того или иного вывода. Фактически это перенос методов, когда-то примененных в промышленности, в область управления знаниями. Основная идея – переход от разовых и не унифицированных методов к конвейерным.